[메타코드 강의 후기] 딥러닝 Deep Learning | Loss Function, 최적화 (1)

메타코드?
메타코드는 IT 대기업 현직자 + 서울대/카이스트 AI 박사 등 검증된 강사진들로 구성되어 있으며,
현직자 특강, 커리어 멘토링, 포트폴리오, 공모전, 채용정보 등 실제 취업에 도움이 될 수 있는 양질의 컨텐츠를 제공하고 있습니다.
평균 제곱 오차 (Mean Squared Error)
MSE는 간단하면서도 강력한 회귀 손실 함수로, 모델의 예측값과 실제값 간의 차이를 정량화하는 방법을 제공합니다.
MSE는 오차의 제곱을 취하는 특성 때문에, 큰 오차값에 대해 더 많은 "패널티"를 부여하게 되며, 이는 오차를 줄이기 위해 모델이 더욱 정교하게 학습하는 데 도움을 줍니다.
MSE의 계산:
이 식에서:
- 은 데이터 포인트의 수입니다.
- 는 각 데이터 포인트에 대한 실제값입니다.
- 는 모델에 의해 예측된 값입니다.
MSE의 주요 특징은 오차가 제곱되기 때문에, 작은 오차는 더 작게, 큰 오차는 더 크게 부각되어 모델이 큰 오차를 특히 더 심각하게 다루도록 합니다.
이로 인해 모델이 더 정밀하게 조정되는 장점이 있습니다.
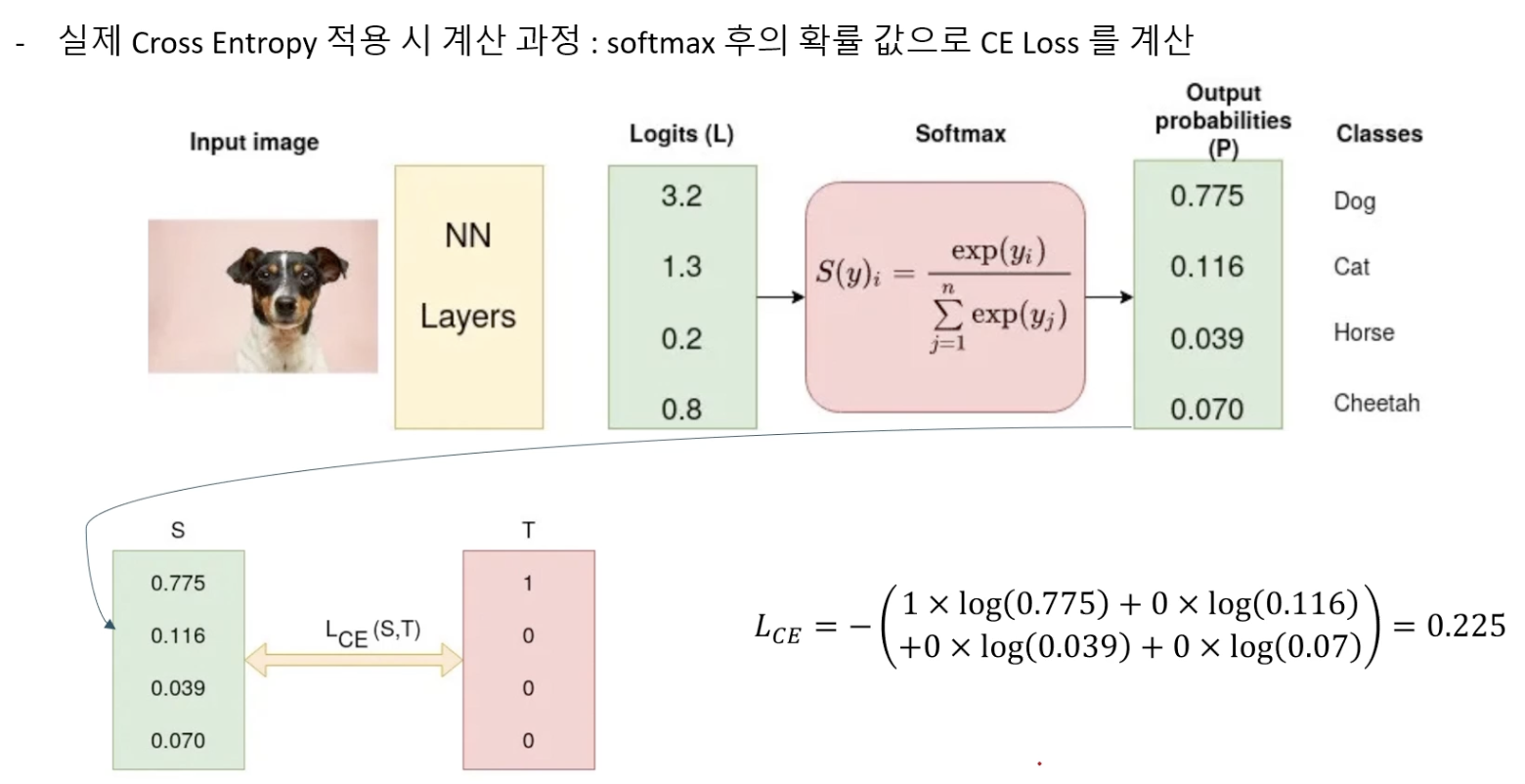
교차 엔트로피 (Cross Entropy)
Cross Entropy는 주로 분류 문제에서 사용되며, 특히 이진 분류나 다중 클래스 분류에서 효과적입니다.
이 손실 함수는 모델의 예측이 실제 레이블과 얼마나 잘 일치하는지를 측정합니다.
Cross Entropy 계산:
이 식에서:
- 는 실제 클래스 레이블(0 또는 1)입니다.
- 는 해당 클래스의 예측 확률입니다.
교차 엔트로피의 핵심은 실제 클래스에 해당하는 확률이 높을수록, 즉 모델이 올바른 예측을 할수록 손실이 감소한다는 점입니다.
반대로, 실제 클래스에 해당하지 않는 확률이 높으면 손실이 증가합니다.
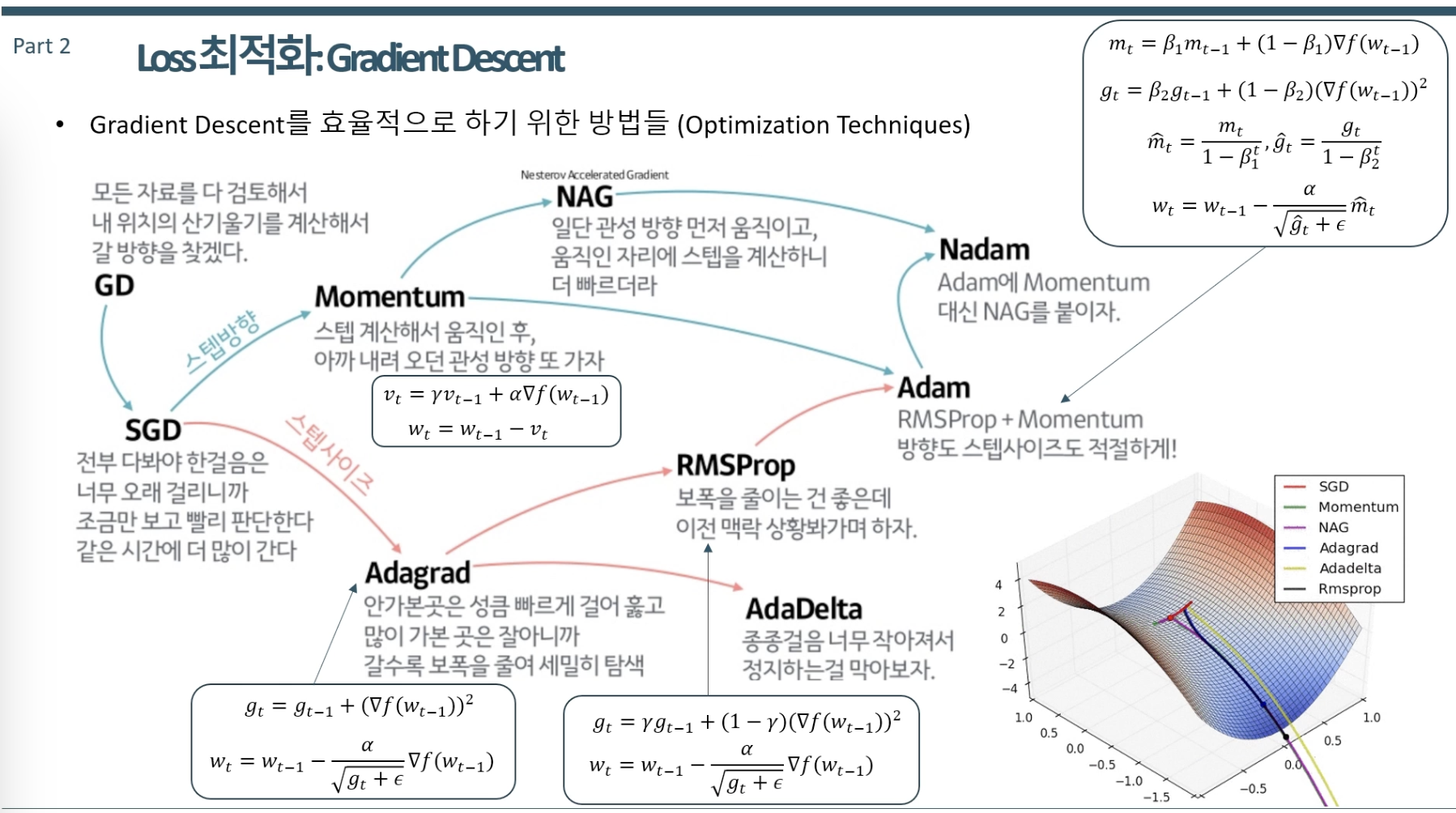
Gradient Descent
모델의 손실 함수를 최소화하기 위해 널리 사용되는 최적화 알고리즘입니다.
주어진 함수의 최소값을 찾기 위해 반복적으로 파라미터를 업데이트하는 방식으로 작동합니다.
기본 원리
그레디언트 디센트의 핵심 아이디어는 손실 함수의 그레디언트(기울기)를 계산하고, 그 그레디언트가 가리키는 방향(즉, 손실을 가장 빠르게 증가시키는 방향)의 반대 방향으로 파라미터를 조정하는 것입니다.
이러한 과정을 통해 손실 함수의 최소값을 찾는것이 목표입니다.

수학적 설명
손실 함수 가 있을 때, 파라미터 에 대한 의 그레디언트 는 의 각 파라미터에 대한 편미분으로 구성된 벡터입니다.
그레디언트 디센트의 각 스텝에서 파라미터는 다음과 같이 업데이트 됩니다:
여기서 는 학습률(learning rate)이라고 하며, 이 값이 얼마나 크게 파라미터를 업데이트 할지를 결정합니다.
학습률이 너무 크면 최소값을 지나쳐 버릴 수 있고, 너무 작으면 수렴하는 데 많은 시간이 걸릴 수 있습니다.
종류
배치 그레디언트 디센트: 전체 데이터 세트를 사용하여 한 번에 그레디언트를 계산합니다. 계산 비용이 매우 높고, 매우 큰 데이터 세트에는 실용적이지 않을 수 있습니다.
확률적 그레디언트 디센트 (SGD): 매 업데이트마다 하나의 훈련 예제를 사용하여 그레디언트를 계산합니다. 이 방식은 더 빠른 수렴을 제공하고, 큰 데이터 세트에도 활용할 수 있지만, 노이즈가 많은 그레디언트로 인해 업데이트가 불안정할 수 있습니다.
미니 배치 그레디언트 디센트: 배치와 SGD의 중간 형태로, 각 업데이트에 소규모의 데이터 집합(미니 배치)을 사용합니다. 이 방법은 효율성과 수렴 속도의 균형을 맞추는데 도움을 줍니다.
핵심 과제와 해결 방안
- 학습률 선택: 적절한 학습률을 찾는 것은 그레디언트 디센트에서 중요한 과제입니다. 너무 높거나 낮은 학습률은 수렴 문제를 일으킬 수 있습니다.
- 지역 최소값 및 안장점: 특히 딥러닝에서, 그레디언트 디센트는 지역 최소값이나 안장점에서 멈추는 문제를 겪을 수 있습니다. 이를 해결하기 위해 모멘텀 기반의 최적화 기법들이 개발되었습니다.
Optimization Techniques
이런 분들께 추천합니다!
서포터즈 강의료 지원을 받아 작성하였습니다