[메타코드 강의 후기] 딥러닝 Deep Learning | Tensor (2)

메타코드?
메타코드는 IT 대기업 현직자 + 서울대/카이스트 AI 박사 등 검증된 강사진들로 구성되어 있으며,
현직자 특강, 커리어 멘토링, 포트폴리오, 공모전, 채용정보 등 실제 취업에 도움이 될 수 있는 양질의 컨텐츠를 제공하고 있습니다.
Attribute : shape, dtype, device
tensor.shape
tensor.shape은 텐서가 갖고 있는 각 차원의 크기를 튜플 형태로 반환한다.
a = torch.tensor([1,2,3,4,5])
a.shape
result: 
b = torch.ones([3,4,5,5])
b.shape
result:
torch.tensor([[1,2,3], [4,5,6], [7,8,9]]) # matrix를 텐서로 정의
result: 
torch.dtype
tensor.dtype은 텐서가 저장하고 있는 데이터의 유형을 설명하는 속성입니다.
a = torch.tensor([1,2,3,4,5])
a.dtype
result: 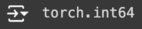
일반적으로 데이터 타입은 다음과 같은 유형이 있습니다.
float32, float64: 부동소수점 수를 나타내며, 실수 연산에 사용됩니다. float32는 32비트 부동소수점 수를, float64는 64비트 부동소수점 수를 저장합니다.
int32, int64: 정수를 나타내며, 인덱싱이나 이산 수학적 연산에 사용됩니다.
bool: 불리언 값을 저장하며, 참 또는 거짓의 두 상태만을 갖습니다.
적절한 데이터 타입을 지정하여 사용하는 것은 시스템 최적화에서 중요한 단계 중 하나입니다. 이를 통해 불필요한 메모리 사용을 줄이고, 계산 속도를 향상시킬 수 있습니다.
tensor.device
tensor.device 속성은 텐서가 저장되거나 계산되는 장치의 정보를 나타냅니다. 이 속성을 통해 텐서가 CPU, GPU, 또는 기타 가속 장치 위에 있는지 확인할 수 있습니다.
a = torch.tensor([1,2,3,4,5])
a.device
result: 
a.to("cuda") # 텐서 a를 CPU에서 GPU로 이동시키는 PyTorch의 메서드입니다.
result: 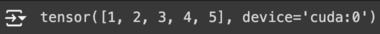
torch.cuda.is_available() # GPU를 사용할 수 있는 환경인지 확인
result: 
torch.cuda.get_device_name(device=0) # GPU 이름 체크(cuda:0에 연결된 그래픽 카드 기준)
result: 
torch.cuda.device_count()
result: 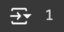
a = torch.tensor([1., 2., 3., 4., 5.]).cuda() # 텐서를 gpu에 할당
b = torch.tensor([1., 2., 3., 4., 5.]).to("cuda") # 텐서를 gpu에 할당
b.device
result: 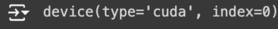
Tensor Aggregation : element-wise 연산, in-place 연산
element-wise 연산
element-wise 연산은 텐서의 각 요소에 독립적으로 수행되는 연산을 의미합니다. 이는 두 텐서의 동일한 위치에 있는 요소들끼리 연산을 수행하는 것을 포함하며, 덧셈, 뺄셈, 곱셈, 나눗셈 등과 같은 기본적인 수학 연산에서 자주 볼 수 있습니다.
Element-wise 연산의 특징
비교적 단순: 각 요소에 동일한 연산이 적용되므로 복잡한 인덱싱이나 추가 메모리를 필요로 하지 않습니다.
병렬 처리 용이: 각 요소의 연산이 독립적이기 때문에 GPU와 같은 병렬 처리 장치에서 매우 효율적으로 실행될 수 있습니다.
브로드캐스팅 지원: 크기가 다른 텐서 간의 연산을 가능하게 하기 위해 작은 텐서가 자동으로 크기를 확장하여 큰 텐서와 같은 형태로 조정됩니다. 이를 브로드캐스팅이라고 합니다.
a = torch.tensor([[1, 2], [3, 4]])
b = torch.tensor([[5, 6], [7, 8]])
print(a)
print(b)
print(a + b)
print(a - b)
print(a * b)
print(a / b)
result: 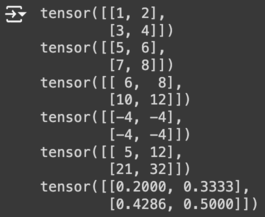
print(a.add(b))
print(a.sub(b))
print(a.mul(b))
print(a.div(b))
result: 
in-place 연산
In-place 연산은 PyTorch에서 특정 연산을 수행하면서 메모리 할당을 새로 하지 않고, 기존의 텐서를 직접 수정하는 방법을 말합니다. 이 방법은 추가 메모리 할당을 줄여서 연산 속도와 메모리 효율성을 높일 수 있습니다.
In-place 연산의 특징
메모리 효율성: 새로운 텐서를 생성하지 않고, 기존 텐서의 값을 직접 변경함으로써 메모리 사용을 줄일 수 있습니다.
주의 필요: 기존 데이터가 수정되므로, 원본 데이터가 필요한 경우 문제가 발생할 수 있습니다. 특히, 딥러닝에서 그라디언트 계산과 같은 연산에 있어서 원본 텐서의 정보가 필요할 때, in-place 연산은 부작용을 일으킬 수 있습니다.
연산자 표현: PyTorch에서 in-place 연산은 연산자 뒤에 _를 붙여 표현합니다. 예를 들어, add_는 덧셈을 in-place로 수행함을 나타냅니다.
print(a.add(b))
print(a)
print(a.add_(b)) # 함수 뒤에 _ 를 붙이면 자기 자신의 값을 바꾸게 된다.
print(a)
result: 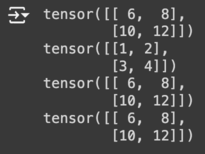
이런 분들께 추천합니다!
서포터즈 강의료 지원을 받아 작성하였습니다