[메타코드 강의 후기] 딥러닝 Deep Learning | 딥러닝이란?

메타코드?
메타코드는 IT 대기업 현직자 + 서울대/카이스트 AI 박사 등 검증된 강사진들로 구성되어 있으며,
현직자 특강, 커리어 멘토링, 포트폴리오, 공모전, 채용정보 등 실제 취업에 도움이 될 수 있는 양질의 컨텐츠를 제공하고 있습니다.
DeepLearning이란 무엇인가?

인공지능(AI), 머신러닝(ML), 딥러닝(DL)은 모두 데이터를 기반으로 한 의사 결정과 예측을 가능하게 하고 있으며, 그 범위와 접근 방식에서 차이가 있다.
인공지능 (Artificial Intelligence, AI): 인공지능은 인간의 지능을 모방하여 기계가 인간처럼 사고하고 학습할 수 있게 하고 있는 기술의 총칭이다. 컴퓨터가 스스로 문제를 해결하거나 결정을 내릴 수 있는 능력을 포함하고 있으며, 자연어 처리, 음성 인식, 이미지 인식 등 다양한 영역에서 활용되고 있다.
머신러닝 (Machine Learning, ML): 머신러닝은 인공지능의 한 분야로서, 알고리즘이 데이터로부터 자동으로 학습하고 개선하고 있다는 기술이다. 명시적인 프로그래밍 없이도 컴퓨터가 경험을 통해 스스로 성능을 향상시킬 수 있음을 의미한다. 머신러닝은 지도학습, 비지도학습, 강화학습으로 나눌 수 있다.
딥러닝 (Deep Learning, DL): 딥러닝은 머신러닝의 한 방식으로서, 인간의 뇌 구조에서 영감을 받은 인공신경망(특히 깊은 신경망)을 사용하여 복잡한 문제를 해결하고 있다. 대량의 데이터에서 패턴을 인식하고 이를 학습하는 데 강력하며, 이미지 인식, 음성 인식, 자연어 처리 등에서 뛰어난 성능을 보이고 있다.
요약하자면, 인공지능은 넓은 의미에서 기계가 인간처럼 지능적으로 행동할 수 있게 하는 모든 기술을 말하며, 머신러닝은 이러한 인공지능을 구현하기 위한 방법 중 하나로 데이터로부터 학습하는 알고리즘의 집합이다. 딥러닝은 머신러닝의 한 방식으로, 깊은 신경망을 이용해 더욱 복잡하고 추상적인 데이터 패턴을 학습하는 데 초점을 맞추고 있다.
기계학습의 분류
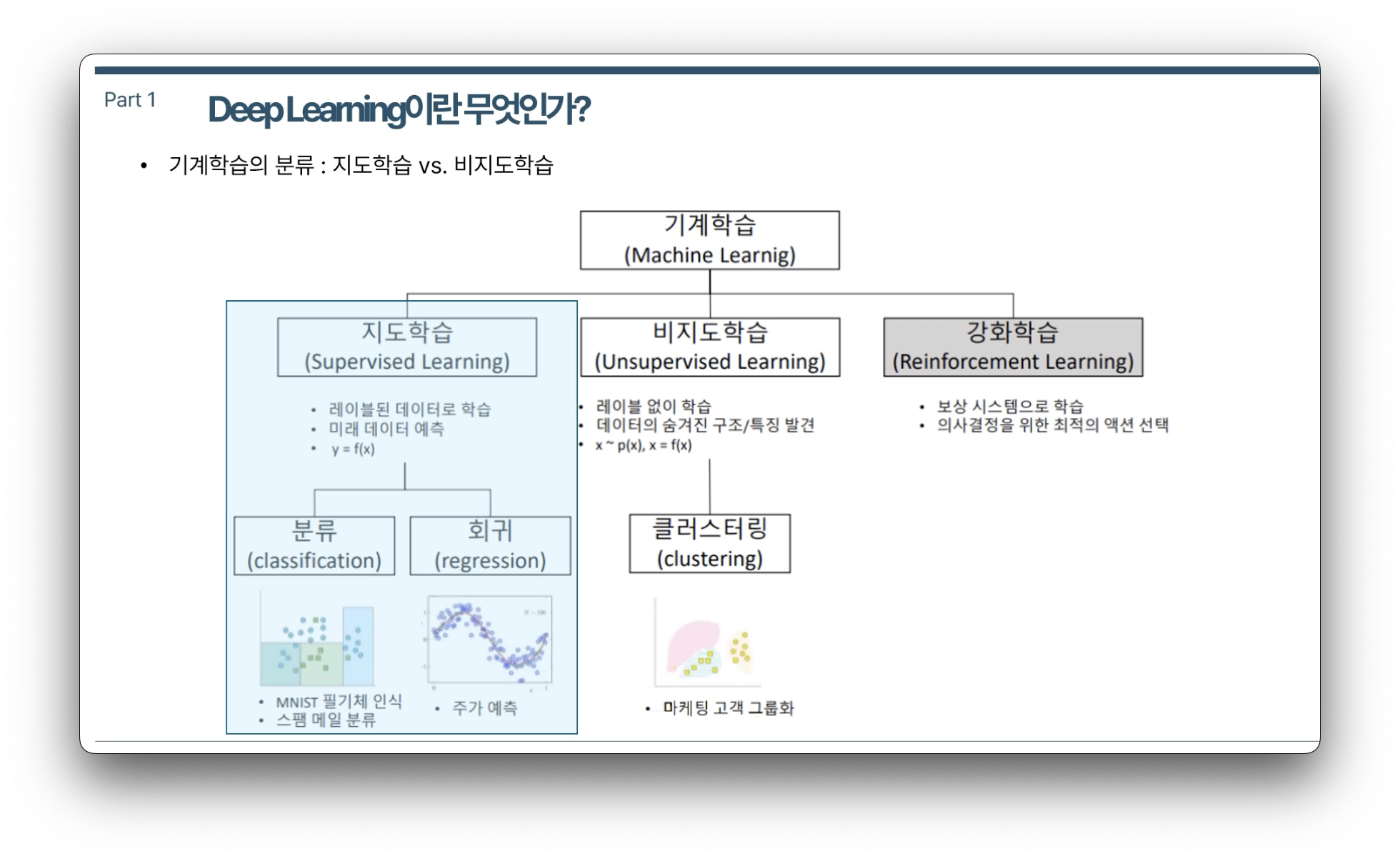
지도학습(Supervised Learning)
- 레이블 데이터를 활용하여 학습
- y=f(x)에서 x: input data y는 label
비지도학습(Unsupervised Learning)
- 미리 정의된 레이블 데이터가 없음
- 데이터의 숨겨진 구조나 특징을 발견하여 학습
강화학습(Reinforcement Learning)
- 보상 시스템으로 학습
- 의사결정을 위한 최적의 액션 선택
ANN(Arificial Neural Network)

기존 모델은 숫자 기반 데이터를 분류하는 것은 가능했지만, 비정형 데이터를 분류하는 것은 어려웠다.
비정형 데이터: 텍스트, 이미지, 비디오, 오디오 등 구조화되지 않은 데이터
특성 추출의 복잡성: 비정형 데이터에서 유의미한 특성을 추출하는 것은 매우 복잡한 작업이다. 예를 들어, 이미지에서 객체를 인식하거나 텍스트에서 주제를 분류하기 위해 사람이 직접 특성을 정의하고 코딩해야 했다. 이 과정은 시간이 많이 소요되고 전문 지식을 필요로 한다.
고차원 데이터의 처리: 비정형 데이터는 종종 고차원의 특성을 가지며, 이를 효과적으로 처리하기 위해서는 상당한 계산 자원이 요구된다. 예전의 기술과 하드웨어는 이러한 고차원 데이터를 효율적으로 처리할 수 있는 능력이 부족했다.
유연성 부족: 초기의 기계학습 알고리즘은 비교적 간단한 데이터 구조에 적합하게 설계되었다. 이러한 알고리즘들은 복잡하거나 추상적인 패턴을 모델링하기에는 유연성이 부족했다.
일반화의 어려움: 비정형 데이터는 불규칙성과 예외가 많기 때문에 이를 일반화하는 것이 특히 어려웠다 이러한 데이터는 오버피팅(과적합)이 일어나기 쉬워, 새로운 데이터에 대한 모델의 성능이 저하되는 문제가 있었다.
데이터 양의 문제: 비정형 데이터는 종종 방대한 양을 포함하고 있으며, 초기의 알고리즘과 시스템은 이런 데이터 양을 처리하기에 충분하지 않았다. 대용량 데이터를 처리하고 학습하기 위한 알고리즘과 하드웨어의 발달이 필요했다.
이는 인공신경망이 도입되면서 이러한 문제들이 상당 부분 해결되었다. ANN은 복잡한 비정형 데이터에서 자동으로 특성을 학습할 수 있는 능력을 가지고 있으며, 딥러닝을 통해 보다 깊은 층의 네트워크를 사용하여 고차원 데이터의 특성을 더 잘 포착할 수 있게 되었다. 이로 인해 비정형 데이터의 분류가 훨씬 효율적이고 정확하게 이루어질 수 있게 되었다.
지도학습 기본구조
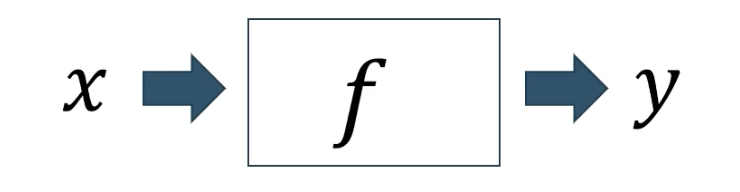
input이 x이고 output이 y일때, y는 x로부터 함수 f를 통해 나온 예측, 추정결과라고 할 수 있다.
여기서 함수 f를 추정하는 과정을 학습이라고 부르며, 좋은 함수를 만드는 것이 주 목적이다.
은 오차를 의미한다.
이때, y의 데이터 타입이 범주형(categorical)이라면 Classification, 연속형(Continuous)이면 Regression이라고 부른다.
학습 데이터셋
(x, y): 학습에 사용하는 데이터셋
x: input data, features, variables, 독립변수, 설명변수 등으로 불린다.
y: output data, label, 종속변수, 반응변수 등으로 불린다.
여기서 주의할 점은 학습에 사용할 데이터셋(train dataset)과 성능 평가에 사용할 데이터셋(test dataset)은 중복되면 안 된다.
성능 평가에 사용할 데이터셋이 학습 데이터셋에 중복되면, 해당 평가 데이터의 정답을 이미 알고있기 때문에 모델을 평가할때 정확한 성능을 판단하기 어렵다.
Regression 예시 (매출에 대한 예측)
TV 광고비, 라디오 광고비, 신문 광고비와 매출의 관계는?

매출(y) = f(TV 광고비(), 라디오 광고비(), 신문 광고비())
일때, Multivariate(변수 x가 여러개) Regression(y가 연속형)이다.
이것을 통해 11번째의 매출을 예측할 수 있다.
Classification 예시

- X: 공부시간 Y: 합격 여부
- 공부시간에 따른 합격 여부 (합격/불합격)
- X: X-ray 결과의 종양의 크기 및 두께 Y: 종양의 여부
- X-ray 결과의 종양의 크기 및 두께를 보고 악성 종양의 여부를 판단 (양성/음성)
- X: 메일 발신인, 제목, 본문 내용 Y: 스팸 메일 여부
- 메일 발신인, 제목, 본문 내용을 토대로 스팸 메일 여부를 판단 (스펨/일반)
이런 분들께 추천합니다!
서포터즈 강의료 지원을 받아 작성하였습니다