스트리밍 음성인식을 위한 overlap 처리
1분 미만
Conformer-CTC 기반의 모델을 사용하여 Streaming ASR을 구현하고자 했습니다.
이 경우 오디오 입력을 실시간으로 처리하여 즉각적인 음성인식 결과를 보여줘야 하기 때문에 음성발화 이후의 음성인식 지연 시간을 최소화하는 것이 중요합니다.
이에 가장 적합하다고 생각한 방법 중 하나는 입력된 오디오를 분할하고 중첩하여 처리하는 것입니다.
이 방식은 인식률이 조금 떨어지지만, 실시간으로 들어오는 데이터를 효율적으로 처리하면서도 문맥적 연결성을 일정 부분 유지할 수 있습니다.
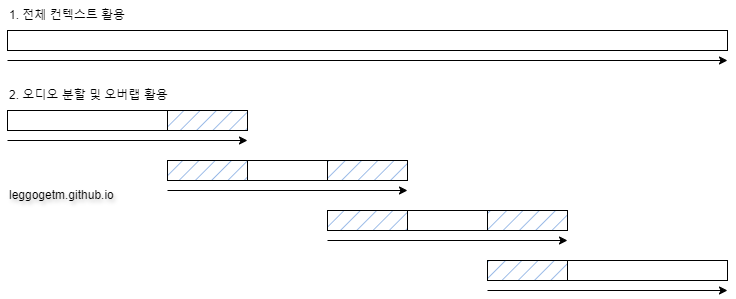
아래에서 오디오를 전체적으로 한 번에 처리하는 방식과 비교해 보았습니다.
오디오 전체를 한 번에 처리
이 접근법에서는 오디오 파일 전체를 모델에 한 번에 입력하여 처리합니다. 이 방식은 문맥 정보를 최대한 활용할 수 있다는 장점이 있습니다.
장점
- 완전한 문맥 이해: 모델이 전체 발화의 문맥을 이해할 수 있기 때문에, 문장의 의미나 발화의 의도를 더 정확하게 파악할 수 있습니다.
- 정보 손실 최소화: 오디오의 시작과 끝에서 발생할 수 있는 비자연스러운 분할로 인한 정보의 손실이 없습니다.
단점
- 실시간 처리 어려움: 오디오 파일 전체를 처리하는 데 시간이 많이 소요되므로 실시간 응용 프로그램에는 적합하지 않습니다.
- 자원 요구량: 긴 오디오 파일을 처리할 때 높은 메모리와 계산 리소스가 필요합니다.
오디오를 분할하고 중첩하여 처리
오디오를 짧은 클립으로 나누고 각 클립을 겹치게 처리하여 연속적인 정보의 흐름을 유지하려 합니다. 이는 실시간 처리를 가능하게 하며, 병렬 처리를 통해 효율성을 높일 수 있습니다.
장점
- 실시간 처리 가능: 짧은 오디오 조각을 빠르게 처리하여 즉각적인 결과를 제공할 수 있습니다.
- 병렬 처리 효율: 오디오 조각을 동시에 여러 개 처리할 수 있어, 전체 처리 시간이 단축됩니다.
- 유연성과 확장성: 다양한 길이의 오디오 클립과 다양한 겹침 설정을 실험하여 최적의 성능을 찾을 수 있습니다.
단점
- 문맥 정보 손실 가능성: 각 조각이 독립적으로 처리될 때, 조각 사이의 연속적인 문맥 정보가 일부 손실될 수 있습니다.
- 복잡성 증가: 오디오 클립이 겹치는 방식을 설계하고 구현하는 것은 추가적인 계산 복잡성을 초래할 수 있습니다.
추가 고려사항
- 오버랩 크기 설정: 오디오 조각의 겹침 크기를 어느 정도로 지정할지 결정하는 것이 중요합니다. 너무 작으면 문맥 정보가 충분히 전달되지 않을 수 있고, 너무 크면 불필요한 계산 부담을 증가시킬 수 있습니다.
- 에러 처리: 겹친 부분에서 발생할 수 있는 인식 오류를 어떻게 처리할지 고려해야 합니다. 예를 들어, 겹치는 부분에서 발생하는 중복 인식 결과를 어떻게 통합할지 정책을 마련할 필요가 있습니다.