Pseudo Labeling 개념
1분 미만
Pseudo Labeling
Paper (2013):
Pseudo labeling은 semi-supervised learning에서 널리 사용되는 기법으로, 레이블이 없는 데이터(unlabeled data)에 가짜 레이블(pseudo label)을 부여하여 이를 학습에 활용하는 방법입니다.
이 방법은 소량의 labeled data를 가지고 대량의 unlabeled data를 최대한 활용하려는 목적을 가지고 있습니다.
주요 과정
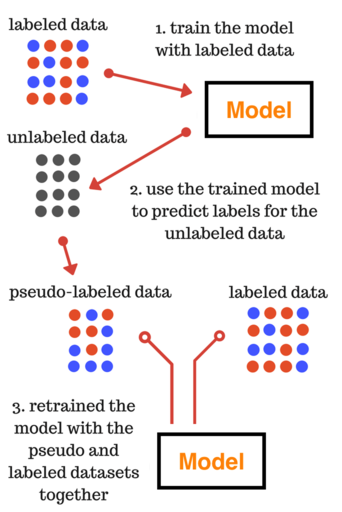
초기 모델 학습:
- 소량의 labeled data(레이블된 데이터)를 이용하여 초기 모델을 학습합니다.
Pseudo Label 생성:
- 학습된 모델을 사용해 unlabeled data에 대한 예측을 수행하고, 예측 확률이 일정 임계치 이상인 데이터에 pseudo-label을 부여합니다. 나머지 데이터는 여전히 unlabeled data 상태로 유지됩니다.
데이터셋 확장:
- 생성된 pseudo-label과 원래의 labeled data를 결합하여 확장된 데이터셋을 만듭니다. 이 데이터셋은 더 많은 데이터를 포함하게 되어 모델 학습에 유리해집니다.
모델 재학습:
- 확장된 데이터셋(labeled data + pseudo-labeled data)을 사용하여 모델을 다시 학습합니다. 이 단계에서 모델은 더 많은 데이터를 기반으로 성능을 향상시킬 수 있습니다.
반복:
- 위 과정(2~4)을 여러 번 반복함으로써 모델은 unlabeled data로부터 점진적으로 학습하여 전체적인 성능을 향상시킵니다. 각 반복 주기마다 모델이 더 신뢰할 수 있는 pseudo-label을 생성하게 되어, 학습 과정이 더욱 정교해집니다.
특징
labeled data 사용:
- 반복 학습 과정에서 항상 원래의 labeled data가 포함됩니다. 이는 모델이 기본적인 정확성을 유지하도록 도와줍니다.
Pseudo-label 갱신:
- 반복될수록 모델이 더 발전하면서 새로운 pseudo-label을 더 정확하게 생성할 수 있으며, 이전에 부여된 label을 갱신할 수 있습니다.
Curriculum Learning 적용:
- 모델은 예측의 신뢰도가 높은 쉬운 샘플부터 학습하고, 점차 어려운 샘플을 학습하면서 성능을 높이는 curriculum learning 원칙이 적용됩니다.
모델 재설정:
- 각 반복 주기 전에 모델 파라미터를 재설정하여 concept drift(시간이 지남에 따라 통계적 특성이 바뀌는 현상)를 최소화할 수 있습니다. 이는 모델이 이전 학습의 편향에서 벗어나 새로운 패턴을 더 쉽게 학습할 수 있게 합니다.
Labeled와 pseudo-labeled 데이터 비율 조절:
- labeled data와 pseudo-labeled data의 비율을 조절하여 학습의 안정성을 유지합니다. pseudo-label이 낮은 품질일 경우, labeled data의 비중을 높일 수 있습니다.
Consistency Regularization:
- 최신 semi-supervised learning 기법들은 pseudo-labeling과 함께 consistency regularization을 사용하여 unlabeled data에 대해 모델의 일관성을 유지하고 더 좋은 성능을 발휘하게 합니다.
장점 및 단점
장점:
- 대량의 unlabeled data를 활용할 수 있어 소량의 labeled data만으로도 모델 성능을 크게 향상시킬 수 있습니다.
단점:
- 잘못된 pseudo-label이 부여될 경우, 모델 성능이 저하될 수 있습니다. 이는 잘못된 학습을 유도하여 최종 결과에 악영향을 줄 수 있습니다.
종료 조건
Pseudo labeling 과정은 다음 중 하나의 조건이 만족될 때까지 반복됩니다:
- 사전 정의된 max epoch에 도달한 시점
- 모델 성능의 개선이 미미한 시점
- 모든 unlabeled data에 pseudo label이 부여된 시점
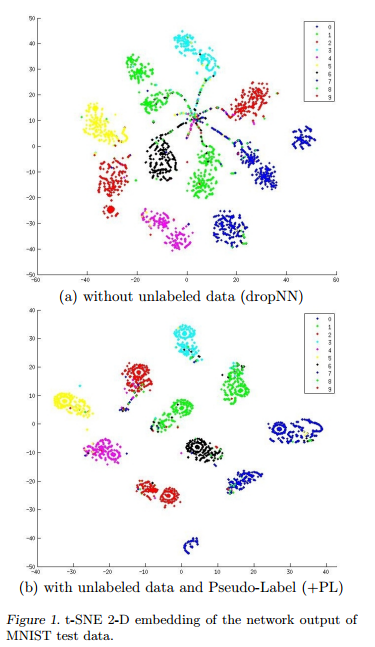
t-SNE 전후비교